Nhận dạng và sửa lỗi văn bản OCR sử dụng các mẫu ký tự sửa lỗi và thuật toán tối ưu là sản phẩm của ThS Phạm Toàn và cộng sự thuộc Vườn ươm Sáng tạo KH&CN Trẻ, TPHCM.
Tự động phát hiện lỗi để sửa
ThS Phạm Toàn chia sẻ, OCR (Optical character recognition - nhận dạng ký tự quang học) là phần mềm/công cụ chuyển đổi các văn bản, hình ảnh của tài liệu in, scan, hay viết tay thành văn bản số, được lưu trữ trên máy tính.
Các văn bản, tài liệu, sách báo được số hóa thông qua các thiết bị/công cụ OCR thường chứa rất nhiều lỗi bao gồm lỗi từ sai chính tả và lỗi từ sai ngữ cảnh, đặc biệt trong các tài liệu lịch sử.
Nguyên nhân là do chất lượng in thấp, ảnh hưởng của việc bảo quản theo thời gian, định dạng chữ (font) hay cách bố trí văn bản (layout) khác biệt. Những lỗi này làm giảm chất lượng và gây hiểu sai đối với các văn bản OCR; đồng thời các tài liệu này không thể dùng ngay cho việc nghiên cứu.
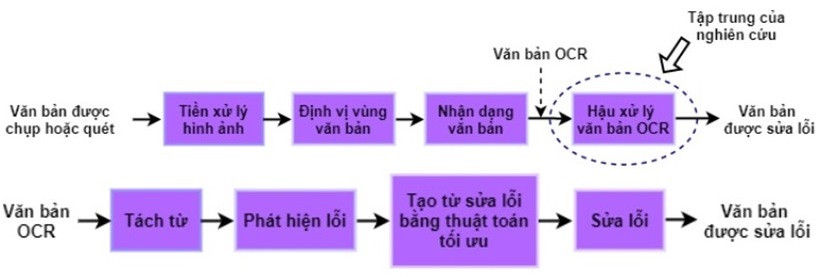
Do đó, việc phát hiện, nhận dạng và sửa lỗi từ trong các văn bản OCR là quan trọng và cần thiết. Hậu xử lý văn bản OCR (OCR post-processing) nhằm nâng cao chất lượng của các văn bản, tài liệu số và là bước cuối cùng của quá trình OCR. Mô hình hậu xử lý văn bản OCR có thể được áp dụng trực tiếp lên văn bản OCR bị lỗi hoặc được tích hợp vào quá trình số hóa văn bản của hệ thống OCR.
ThS Toàn và nhóm nghiên cứu đề xuất mô hình mới tự động sửa lỗi văn bản OCR sử dụng các mẫu ký tự ngẫu nhiên kết hợp thuật toán tối ưu để phát hiện.
Nhóm nghiên cứu đã xây dựng các tập dữ liệu training và test tiêu chuẩn để huấn luyện, đánh giá mô hình. Trong đó, dữ liệu văn bản cần được canh hàng theo mức từ và mức ký tự; xây dựng các bảng sửa lỗi ký tự từ tập dữ liệu, viết chương trình tạo bảng sửa lỗi ký tự tương ứng; xây dựng mô hình post-processing bao gồm các bước xử lý tách từ, phát hiện lỗi từ, tạo từ sửa lỗi và xếp hạng từ sửa lỗi, viết chương trình chạy mô hình tương ứng; đề xuất mô hình áp dụng thuật toán tối ưu trong việc phát hiện và tạo từ sửa lỗi, viết chương trình cho mô hình áp dụng thuật toán tối ưu tương ứng; so sánh, đánh giá kết quả phát hiện và sửa lỗi của mô hình đề xuất với các mô hình khác…
Cải tiến chất lượng các văn bản lưu trữ
Nhóm đã đưa ra giải pháp sửa lỗi văn bản OCR dựa trên các mô hình ngôn ngữ n-gram ở mức từ và mô hình tạo từ sửa lỗi sử dụng các mẫu ký tự sửa lỗi ngẫu nhiên theo các vòng lặp tiến hóa (evolution loop). Mô hình đề xuất khai thác cả đặc tính ngôn ngữ và đặc tính lỗi OCR trong tập dữ liệu huấn luyện.
Các đặc điểm ngôn ngữ bao gồm tính tương tự, tần suất từ đơn và tần suất ngữ cảnh; đặc tính lỗi OCR dựa trên xác suất chỉnh sửa ký tự. Cụ thể, mô hình đề xuất bao gồm bốn giai đoạn xử lý theo thứ tự như sau: Tách từ, phát hiện lỗi, tạo từ sửa lỗi và sửa lỗi.
Mô hình đề xuất cũng được thí nghiệm đánh giá trên tập văn bản chuyên khảo tiếng Anh. Kết quả cho thấy, trong mô hình sử dụng thuật toán tối ưu, các từ sửa lỗi được tìm thấy thông qua các mẫu ký tự sửa lỗi ngẫu nhiên và được điều khiển theo các vòng lặp tiến hóa HC (thuật toán tối ưu leo đồi). Mô hình đề xuất có phương pháp trích xuất thông tin lỗi OCR đơn giản hơn vì các mẫu ký tự sửa lỗi được học trực tiếp từ tập dữ liệu huấn luyện.
Việc chạy lại thuật toán cũng như chọn lại vị trí ký tự ngẫu nhiên được áp dụng để giúp thuật toán leo đồi từ các từ cơ sở đúng và cải thiện chất lượng sửa lỗi. Mô hình đề xuất được chứng minh là hoạt động tốt hơn các phương pháp hậu xử lý văn bản OCR khác trên cùng tập dữ liệu văn bản OCR tiếng Anh.
Các thí nghiệm khác nhau về tính ngẫu nhiên của thuật toán được đề xuất chứng minh rằng nó ổn định với độ tin cậy cao dưới các cài đặt tham số thích hợp.
Theo ThS Phạm Toàn, kết quả này có thể mở rộng triển khai ứng dụng để phát triển thành công cụ nhận dạng và sửa lỗi văn bản OCR tiếng Việt dưới dạng ứng dụng trên web hay di động.
Điều này góp phần nâng cao chất lượng văn bản tiếng Việt đã được số hóa qua các công cụ OCR. Nghiên cứu cũng có thể được triển khai ứng dụng để cải tiến chất lượng các văn bản, tài liệu số được lưu trữ tại các thư viện, các cơ sở dữ liệu số.